At Experion Technologies, we enable future-ready enterprises to break free from monolithic data systems through modern data mesh architecture, delivering decentralized intelligence, domain-level agility, and high-impact business insights.
In the era of AI, cloud-native systems, and IoT, the complexity of enterprise data ecosystems has exploded. Traditional centralized data platforms, once effective, are now straining under the pressure of scale, latency, and organizational diversity. Large, centralized data lakes and rigid warehouses often become bottlenecks, limiting speed, agility, and trust in data operations.
This is where Data Mesh emerges, not just as a technological shift, but as a new data architecture paradigm, enabling distributed data ownership, scalability, and self-service across business domains.
What is Data Mesh?
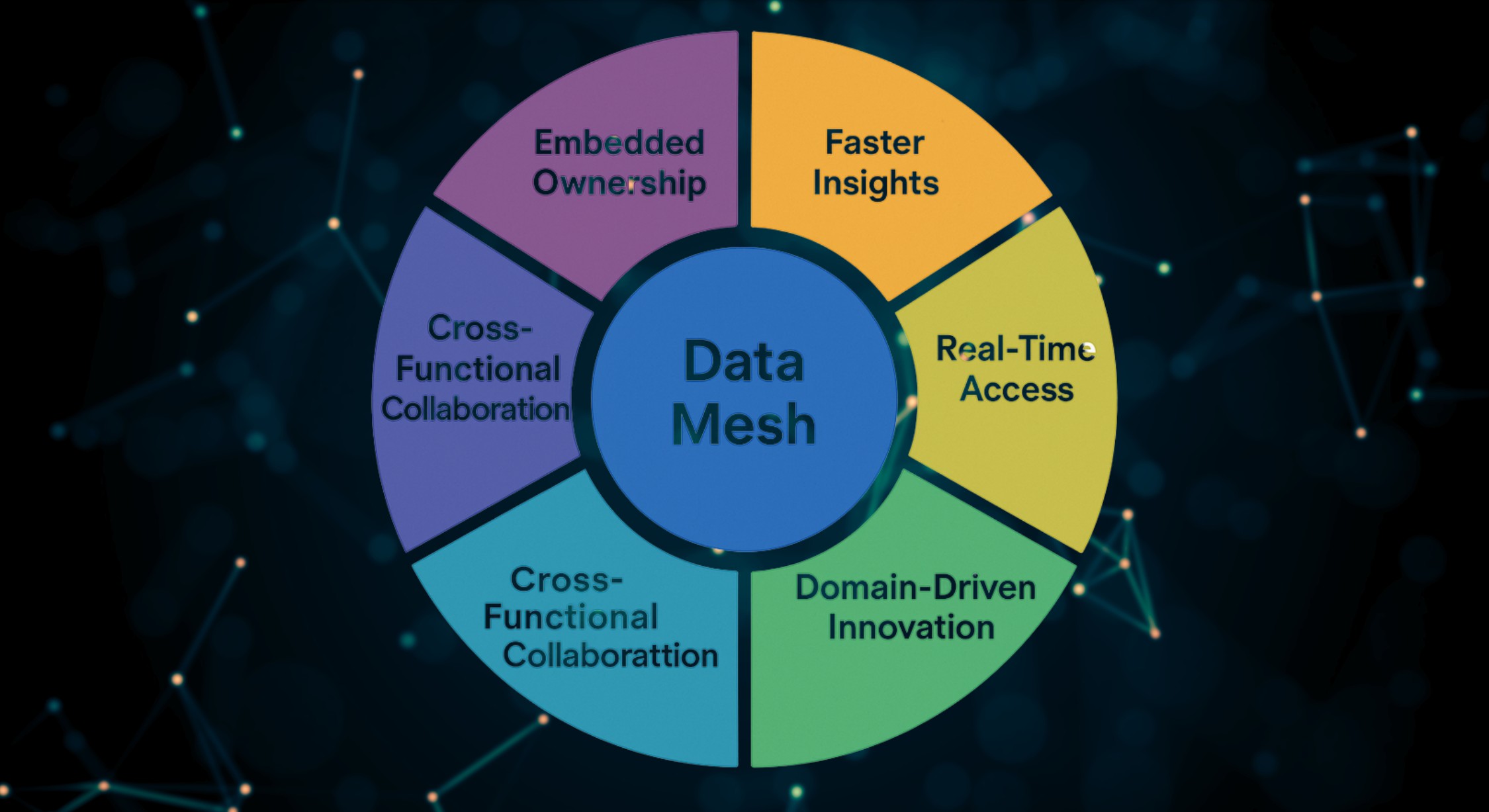
Data Mesh is a decentralized approach to data architecture that emphasizes domain-oriented ownership, data as a product, self-service infrastructure, and federated governance. It was first introduced by Zhamak Dehghani and has since evolved into a leading framework for scalable, modern data platforms.
Unlike traditional centralized models, which rely on a small team managing all data pipelines and assets, data mesh empowers each business domain to own, govern, and serve their data, just like they would manage a software product.
| Feature | Centralized Data Model |
Data Mesh |
|
Ownership |
Central team | Domain teams |
|
Data Modeling |
Generic, one-size-fits-all |
Domain-specific, contextual |
|
Speed & Agility |
Slower |
Faster, parallel |
|
Governance |
Strict central |
Federated, aligned |
| Innovation | Bottlenecked |
Distributed |
Core Principles of Data Mesh
- Domain-Oriented Ownership
Data is managed by domain teams who understand its context, quality, and business value. Marketing, Sales, HR, Finance, each becomes a data owner. - Data as a Product
Each domain is responsible for making their data discoverable, trustworthy, and usable by others, treating it like a product with SLAs and consumer satisfaction in mind. - Self-Service Data Infrastructure
Data teams are supported by central platform teams that build tooling for ingestion, cataloging, monitoring, and access, enabling domains to operate independently. - Federated Governance
While domains operate autonomously, a shared framework ensures compliance, interoperability, metadata standards, and lineage visibility across the enterprise.
Together, these principles decentralize data responsibility, improve data agility, and align data systems with organizational structures.
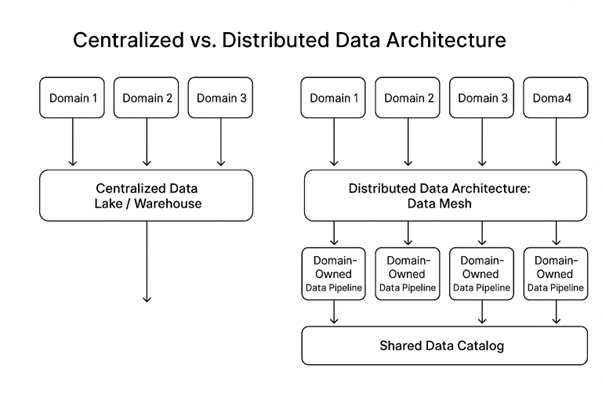
Evolution of Data Architecture: From Warehouses to Mesh

For years, enterprises have structured their data strategies around centralized data warehouses and data lakes, systems that promised a unified source of truth by consolidating data from disparate sources into one platform. While effective in the early stages of digital transformation, these traditional architectures are now struggling to keep pace with the demands of modern, data-intensive organizations.
Limitations of Traditional Centralized Architectures
As businesses grow more complex and data-hungry, the shortcomings of centralization become apparent:
Bottlenecks
Centralized data teams often become overwhelmed as every department, marketing, finance, operations, sales, depends on them for data ingestion, cleaning, modeling, and delivery. This over-reliance creates a bottleneck that slows down project delivery and hinders business agility.
Data Silos
Ironically, even centralized architectures can create silos, particularly when domain-specific knowledge isn’t embedded into the data modeling process. A central team may not fully understand the context or nuances of each department’s data, resulting in misinterpretations, misalignments, or underutilized assets.
Latency
Traditional ETL (Extract, Transform, Load) processes often involve scheduled batch jobs, which introduce time lags. This latency is unacceptable in scenarios requiring real-time analytics, such as fraud detection, dynamic pricing, or operational monitoring, where data freshness directly impacts outcomes.
Low Trust
When users lack visibility into how data is collected, transformed, and validated, they begin to doubt its accuracy. Without domain-level context, it becomes difficult to ensure quality and traceability, leading to hesitation in data-driven decision-making.
The Shift Toward Distributed, Domain-Driven Models
To overcome these limitations, forward-thinking organizations are embracing a new model: Data Mesh, a distributed data architecture that aligns technical systems with business domains.
Unlike traditional models that consolidate data into a single platform, Data Mesh decentralizes both ownership and accountability, assigning responsibility for data to the domain teams that generate and use it. Each team becomes a data product owner, responsible for delivering high-quality, usable, and trusted datasets to the rest of the organization.
|
Traditional Model |
Data Mesh Model |
|
Central team supports all data |
Domains own their data |
| Long delivery cycles |
Parallel development |
|
Poor domain context |
Domain-specific data modeling |
|
Centralized governance |
Federated policies + autonomy |
This domain-driven approach brings several key advantages:
- Faster Delivery of Insights:
With data stewardship embedded within each department, changes can be implemented and published without waiting for a central data team. - Improved Data Quality and Relevance:
Domain teams understand their data best. By taking ownership, they can ensure better data modeling, annotation, and maintenance, rooted in business context. - Increased Scalability:
Rather than scaling a single team to support all departments, each domain scales its own capabilities as needed, supported by self-service infrastructure. - Empowered Platform Teams:
Central IT or data platform teams transition from bottlenecks to enablers, focusing on delivering standard tools for observability, access control, lineage tracking, and compliance, freeing up domain teams to innovate independently.
Understanding Data Mesh Architecture
Data Mesh represents a profound shift in how enterprises design, govern, and scale their data ecosystems. It is both a sociotechnical framework, concerned with people, culture, and processes, and a platform strategy that defines how data systems and tools are built to support decentralized, domain-driven practices.
Instead of routing all data through centralized pipelines and teams, data mesh distributes responsibility to individual business domains, empowering them to own and serve their data as products. This transformation requires a rethinking of team roles, infrastructure layers, and governance policies to unlock agility and scalability.
|
Role |
Responsibilities |
|
Data Product Owner |
Own quality, SLAs, usability of domain data |
|
Domain Data Team |
Build pipelines, enrich & validate data |
|
Platform Team |
Build self-service tools, not manage data |
| Governance Group |
Set standards, monitor compliance, enable traceability |
Key Building Blocks of a Data Mesh Architecture
To implement data mesh successfully, organizations must enable several core components. These are not just technologies, but design principles that ensure decentralization does not devolve into data chaos.
- Data Product Owners
In the data mesh model, each domain, be it Sales, Marketing, Finance, or Supply Chain, assigns data product owners responsible for the lifecycle of domain-specific datasets.
- These owners ensure that data is reliable, documented, discoverable, and trustworthy.
- Their responsibilities include maintaining high standards of quality, ensuring availability and usability, and fulfilling SLAs (service-level agreements).
- They act as the bridge between producers and consumers, understanding both the source systems and the needs of downstream users.
Example: In a retail company, a data product owner in the inventory domain would manage product availability data, ensuring it’s real-time, accurate, and accessible to analytics, logistics, and merchandising teams.
- Domain Data Teams
Supporting the product owners are domain data teams, composed of data engineers, analysts, and subject matter experts embedded within each functional area.
- These teams handle data ingestion, transformation, validation, enrichment, and publication.
- Their deep understanding of domain context ensures more accurate and relevant modeling of data.
- They collaborate directly with stakeholders within their business unit, reducing communication lag and dependency on central teams.
This cross-functional model brings data operations closer to the source, enhancing quality and relevance while enabling faster iteration.
- Self-Service Platform
To empower domain teams without overwhelming them with infrastructure concerns, a central platform team builds and maintains a shared self-service data platform.
This platform typically includes:
- Data cataloging tools for discovery and metadata tagging (e.g., Alation, Collibra).
- Data lineage and version control to trace changes and ensure reproducibility.
- Pipeline orchestration tools (e.g., Airflow, Dagster) for automating ETL/ELT processes.
- Security and access controls (e.g., Immuta) to ensure compliance.
- Monitoring and observability dashboards to track data freshness, usage, and quality.
The platform team doesn’t manage data itself but provides enablement tools to allow domains to build and operate data products independently, safely and at scale.
- Governance and Observability
A hallmark of the data mesh approach is federated governance, striking a balance between domain autonomy and enterprise-wide consistency.
- Federated governance means that each domain enforces local policies, while also adhering to global standards for security, privacy, lineage, and interoperability.
- Common elements include data contracts, standardized schemas, access policies, audit logs, and metadata definitions.
- Observability ensures that both data producers and consumers have transparency into data pipelines, lineage, anomalies, and quality metrics.
This model avoids the rigidity of central governance and the fragmentation of no governance by introducing “guardrails, not gates.”
How Data Mesh Promotes Agility and Business-Aligned Ownership
The primary strength of data mesh lies in its ability to align data operations with business domains, accelerating time to insight and reducing systemic friction.
Encourages Cross-Functional Collaboration Within Domains
By embedding data responsibilities within domain teams, data mesh promotes tight collaboration between technical experts and business users. Teams work closer to their data sources and consumers, enabling:
- Faster feedback loops
- More accurate modeling of real-world processes
- Greater ownership and accountability
Enables Real-Time Data Delivery and Consumption
Because each domain is responsible for its own data pipelines and APIs, data mesh allows for faster ingestion and processing of real-time events. This is crucial for domains like:
- Fraud detection in financial services
- Inventory optimization in retail
- Patient monitoring in healthcare
Data doesn’t have to travel through central bottlenecks—it can be consumed directly at the source.
Aligns Technical Systems with Business Structures and Priorities
In traditional systems, centralized teams often lack the domain expertise to prioritize what matters most to business units. In contrast, data mesh aligns technical capabilities with business goals by giving:
- Ownership to the teams closest to the data
- Autonomy to innovate based on evolving needs
- Clear insight into the usage and value of data.
This tight alignment improves prioritization, accountability, and agility.
Reduces Dependency on Central Teams, Improving Time to Insight
Central data teams are typically overburdened, leading to backlogs, long ticket queues, and frustrated stakeholders. Data mesh eliminates this bottleneck by enabling:
- Parallel development of data products across domains
- Faster experimentation without long dependency chains
- Local control over delivery timelines and resource allocation
The result is a system that scales horizontally with the business.
Visualizing Data Mesh Architecture
Imagine an enterprise where each business domain owns a “data product”:
- These products are modular, documented, and discoverable via a central catalog.
- They expose APIs for real-time access, support versioning, and include metadata and SLAs.
- All products are interconnected through a federated layer of governance and infrastructure, ensuring trust, security, and consistency.
This mesh of interconnected data nodes mimics a modern microservices architecture, but for data. It replaces monolithic pipelines with domain-owned products, stitched together with tooling that ensures control without centralization.
Benefits of Adopting a Data Mesh Approach
The shift to a distributed data architecture brings several enterprise-wide benefits:
- Scalability Across Functions:
Each domain can scale its data capabilities independently, removing friction and dependency on central bottlenecks. - Faster Access to High-Quality, Domain-Specific Data:
With data owned and served by the teams that create it, consumers get better accuracy, faster delivery, and deeper context. - Encourages Data Ownership and Accountability:
Domains take pride and responsibility in maintaining the quality and usability of their data products. - Reduces Bottlenecks on Central Teams:
The central data team evolves into an enablement layer, building tools and standards while shifting operational load to the edge.
|
Benefit |
Business Impact |
|
Scalability Across Functions |
Agile domain expansion without friction |
| Faster Access to Quality Data |
Improved decision-making, lower latency |
|
Encourages Data Ownership |
Better quality control and stewardship |
|
Fewer Bottlenecks on Central Teams |
More innovation and faster experimentation |
Challenges and Considerations in Implementing Data Mesh
Despite its promise, transitioning to data mesh architecture presents several challenges that organizations must address carefully.
- Organizational Change Management:
Data mesh requires a cultural shift toward shared ownership, cross-functional collaboration, and product thinking. Leaders must support this transformation with clear roles, KPIs, and incentives. - Enabling Cross-Domain Governance:
Without effective governance, decentralization can lead to inconsistency and data chaos. A federated model must balance autonomy with compliance, security, and interoperability. - Building Robust Self-Serve Infrastructure:
A scalable mesh requires robust tooling: data catalogs, pipeline automation, access controls, and monitoring that empower domains while maintaining standards. - Ensuring Data Discoverability and Interoperability:
Data products must be well-documented, versioned, and standardized so that others can easily find, trust, and use them across the organization.
| Challenge | What to Watch For |
Mitigation Strategy |
|
Org Change Management |
Resistance from teams |
Leadership backing, clear KPIs |
|
Cross-Domain Governance |
Inconsistent standards |
Federated policies, shared metadata schema |
|
Lack of Self-Service Platform |
Overload on central teams |
Invest in automation, discovery, access tools |
| Poor Discoverability | Data chaos, redundancy |
Enforce documentation, SLAs, versioning |
Data Mesh vs Data Fabric: Key Differences and Use Cases
Both data mesh and data fabric address data complexity and integration, but they differ significantly in their approach and philosophy.
| Comparison | Data Fabric |
Data Mesh |
|
Data Volume |
Medium – High |
High – Very High |
| Governance | Centralized, Medium-to-High complexity | Decentralized, High-to-Very High complexity |
| Data Maturity | Medium – High |
Low – Medium |
|
Data Complexity |
Low – Medium | High – Very High |
| Approach | Technology-centric, architecture-driven | Organization-centric, domain-driven |
| Cost & TTM | Low – Medium |
Medium – High |
|
Self-Serve Capability |
Good | Best |
| Skill Level | High |
Medium |
|
Automation |
Centralized | Isolated (needs augmentation) |
| Use Cases | IoT Analytics, Customer 360 |
CDP (Customer Data Platform), Product 360 |
Which to Choose and When?
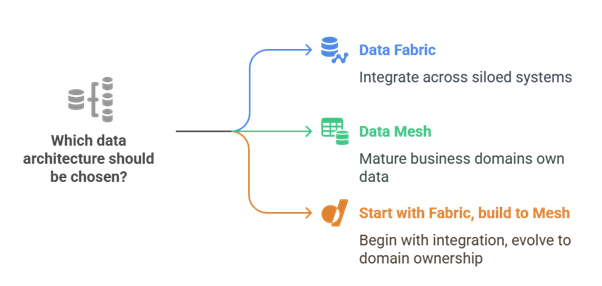
- Choose Data Fabric if your priority is technical integration across multiple systems, or you’re building a central data hub for analytics.
- Choose Data Mesh when your organization has multiple domains, rapid scaling needs, and requires domain-level autonomy for agility and innovation.
At Experion Technologies, we help enterprises choose and implement the right architecture, be it data mesh, data fabric, or a hybrid, based on their specific needs and maturity.
Real-World Use Cases of Data Mesh
- Retail:
Local teams manage product and inventory data for their region. With data mesh, regional teams can publish real-time sales, stock, and customer insights, improving pricing and promotions. - Financial Services:
Risk, compliance, and fraud teams in different departments manage their own data products. A data mesh ensures secure, compliant, yet agile data handling, enabling faster decision-making. - Healthcare:
Patient data from labs, clinics, and operations is handled by domain teams. Mesh architecture provides clear ownership, data quality, and interoperability while ensuring privacy and compliance. - Technology Companies:
A shared platform empowers product, marketing, and support teams to build tailored analytics products, fostering experimentation, instant feedback, and quicker innovation.
Tools and Technologies Enabling Data Mesh
Implementing a successful data mesh architecture requires a modern data platform stack that supports discovery, governance, automation, and scalability.
Key Platform Components
- Data Cataloging:
Tools like Collibra, Alation help catalog data products, enforce metadata standards, and enhance discoverability. - Data Observability:
Platforms such as Monte Carlo and Databand provide insights into data health, lineage, and anomalies. - Data Orchestration:
Workflow tools like Apache Airflow and Dagster automate pipeline execution and enable data product deployment. - Access Control and Lineage:
Solutions like Immuta and Amundsen help manage permissions, lineage tracking, and audit trails across domains. - Cloud-Native Infrastructure:
Mesh-ready environments are supported by platforms like Databricks, Snowflake, AWS Lake Formation, and Google BigQuery that offer modular, scalable architecture and automation capabilities.
Best Practices for Transitioning to a Data Mesh Model
Adopting a data mesh architecture is not a simple plug-and-play switch, it’s a significant organizational and cultural transformation. To ensure success and reduce risk, enterprises should approach this shift incrementally, with structured strategies, aligned teams, and robust platform support.
- Start with a Pilot
Transitioning to a data mesh model should begin with a limited, well-defined pilot to test the model’s principles and infrastructure within a controlled scope.
- Choose one or two domains, preferably with mature teams and clear data pain points.
- Implement core components: data product ownership, self-service pipelines, and federated governance.
- Measure success based on delivery speed, data quality improvements, and domain satisfaction.
- Use the pilot to uncover gaps in tooling, governance, or skills before scaling organization-wide.
Example: Start with the sales and marketing domains, which often already have strong analytics maturity and can showcase quick wins with measurable impact.
- Define SLAs and Ownership Clearly
A fundamental tenet of data mesh is treating data as a product. This requires domains to establish and honor clear Service-Level Agreements (SLAs) for every data product.
- Specify refresh rates, delivery timelines, data availability windows, and quality thresholds.
- Assign named data product owners with responsibility for maintaining, updating, and supporting their datasets.
- Promote accountability by tying SLAs to business KPIs and operational objectives.
This clarity builds trust between producers and consumers, reducing misunderstandings and ensuring reliability.
- Foster a Product-Thinking Culture
Data mesh is as much about mindset as it is about architecture. Domain teams must evolve from pipeline operators to product managers of data assets.
- Emphasize consumer empathy, understanding how internal users will access, use, and rely on the data.
- Encourage documentation, versioning, and intuitive interfaces, just like any good product.
- Promote continuous feedback loops so teams can iterate and improve data offerings over time.
Adopting product-thinking ensures that data products are maintained, discoverable, and valuable, rather than becoming technical artifacts left unused.
- Invest in Platform Enablement
Domain teams can only thrive if supported by a robust self-service platform that abstracts away infrastructure complexity.
- Build a centralized platform that offers data discovery, lineage, quality checks, access management, and pipeline automation.
- Prioritize usability, modularity, and extensibility, so that domain teams can innovate without waiting on central IT.
- Ensure the platform is well-documented, well-supported, and continuously improved in response to domain feedback.
This foundation transforms data from a service bottleneck into an organizational asset, enabling rapid domain-level innovation.
Future of Data Mesh and Distributed Data Architecture
As enterprise data landscapes continue to grow in complexity, data mesh is poised to shape the next generation of data strategies. It aligns perfectly with broader trends in decentralization, composable technologies, and intelligent automation.
- Enterprise-Wide Decentralization
In today’s large, global organizations, centralized teams struggle to scale across regions, products, or departments. Data mesh offers an organizational structure that mirrors the complexity of the business.
- As companies expand, each region or division can manage its own data domains while staying compliant through federated governance.
- Business agility improves as decisions are driven by domain-specific insights delivered in real time.
Result: Enterprises will become more responsive, resilient, and regionally autonomous without losing standardization.
- AI/ML Integration
Data mesh will increasingly become the backbone of AI and machine learning systems.
- The quality of AI models is determined by the data they’re trained with. Domain-specific data products offer cleaner, richer, and more contextualized inputs.
- Mesh architecture enables real-time streaming pipelines that feed continuous learning models for fraud detection, recommendation engines, demand forecasting, and more.
- Federated data governance ensures compliance with evolving data privacy regulations like GDPR and HIPAA.
Result: AI systems become smarter, more ethical, and better aligned with business-specific needs.
- Internal Data Marketplaces
As data mesh matures, enterprises will build internal data marketplaces, platforms where domain teams publish, discover, and subscribe to data products.
- Teams can browse available datasets, assess quality scores, view lineage, and integrate them instantly.
- Monetization models may emerge internally, where high-value data domains receive budget incentives for delivering widely adopted products.
Result: Data becomes a measurable asset, driving transparency, reuse, and innovation across the enterprise.
- Composable Data Stacks
The next evolution of data architecture will be modular and plug-and-play, enabling organizations to adapt quickly to new use cases and technologies.
- Instead of monolithic platforms, enterprises will adopt interoperable tools across orchestration, observability, cataloging, and access control.
- Hybrid deployments across data mesh, data fabric, and edge computing will become the norm, allowing flexibility by use case.
Result: Enterprises build composable data stacks that are scalable, agile, and future-proof.
Looking Ahead
The future of data mesh architecture isn’t just technical, it’s transformative. It redefines how organizations think about:
- Data ownership and stewardship
- Interdisciplinary collaboration
- Scalability and real-time intelligence
- Enterprise-wide enablement and innovation
As data becomes increasingly central to digital transformation and AI-led decision-making, data mesh will serve as a foundation for next-generation data maturity.
Experion Technologies partners with enterprises at every stage of the journey, from strategy and platform design to implementation and scale-out, ensuring a smooth and successful transition into the world of distributed, intelligent, and business-aligned data architecture.
Conclusion
 The rise of Data Mesh – Distributed Data Architecture represents a foundational shift in how enterprises think about data. Moving beyond centralization, mesh enables ownership, agility, and innovation at scale, aligning data delivery with business structures and velocity.
The rise of Data Mesh – Distributed Data Architecture represents a foundational shift in how enterprises think about data. Moving beyond centralization, mesh enables ownership, agility, and innovation at scale, aligning data delivery with business structures and velocity.
Experion Technologies helps organizations unlock the power of data mesh architecture, designing platforms and roadmaps tailored to their growth, compliance, and digital transformation needs.
Key Takeaways
- Data Mesh enables decentralized, domain-driven data architecture aligned with business agility.
- Core principles include domain ownership, data-as-a-product, self-service infrastructure, and federated governance.
- It breaks away from the bottlenecks and rigidity of centralized data lakes and warehouses.
- Compared to Data Fabric, Data Mesh focuses more on organizational structure than technical integration.
- Use cases span retail, finance, healthcare, and tech, with strong ROI through scalability and responsiveness.
- The right tools, cataloging, observability, orchestration, are key to mesh success.
- Experion Technologies offers strategic, architectural, and platform support to enable scalable data mesh implementation.
Let’s co-create a data foundation that’s scalable, intelligent, and aligned with your business goals.
Connect with Experion’s data strategy team today to explore how Data Mesh can unlock agility, trust, and real-time intelligence across your organization.